Absurd debug : why is the website DOSing Spotify ?
For a bit of context, I help keep alive a french music-oriented website, before an upcoming overhaul. Technically, it is the typical nobody-knows-how-it-still runs Wordpress that has been put together with a bunch of plug-ins having side effects all around that you cannot decently reason about. Touching anything breaks something elsewhere, and knowledge of the inner workings has been lost as the original builders left.
The website runs on shared hosting, which should be 10 to 100 times over-powered for the kind of content served. But somehow the site slows down to being totally unavailable for a full day at times.
With the shared hosting provider’s logs, I noticed the website somehow started to send over 18k outbound requests per minute during that day. With the attack surface of a typical website built that way, things started to smell bad. The drop to zero is the moment I fixed it though :^) .
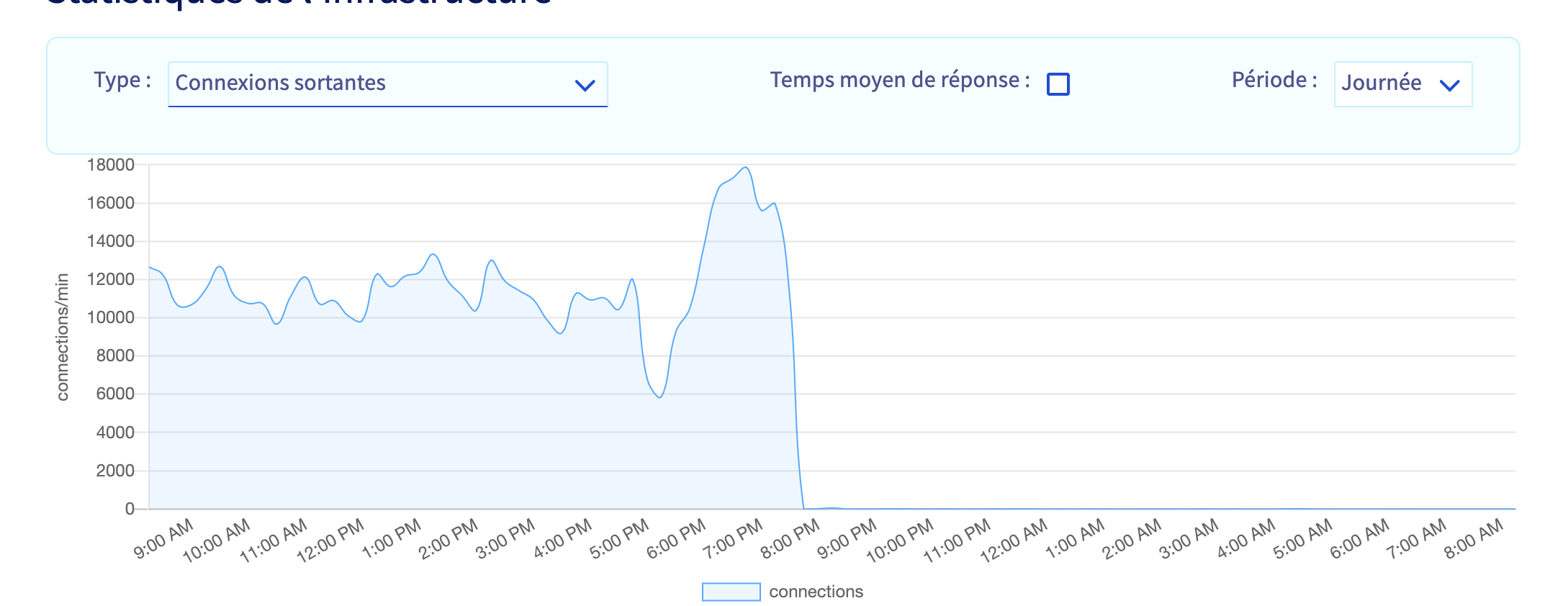
Most requests issued a 5XX response, until that same moment (light blue is 5XX, darker blue is 2XX). There was a sudden peak of 5XX a bit later, that I will have to investigate too, but nothing too bad compared to the rest of the day :
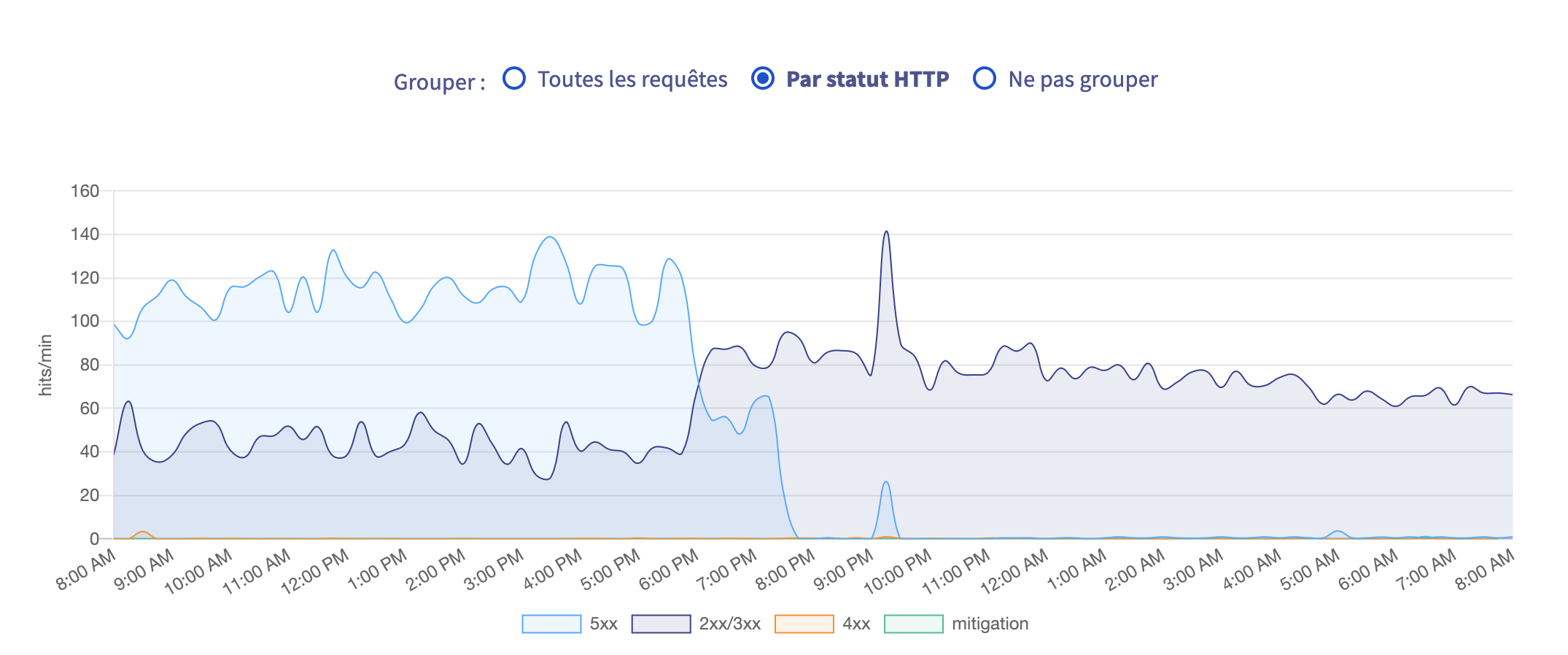
Going through the inbound access logs, I see that this day, bots went a bit over the top on the search page of the website. The search page is made of a lot of buttons, for music genres, thematic selections, and time of release. You can combine multiple genres, selections, and times, and when you click on a filter, all the URLs of the other filters (which are just link tags) change. So this page can be seen as an almost-infinite URL factory for all filter combinations, to be consumed by bots. What is funny is that if those links were buttons with actions triggered by JS, that would certainly not have happened. Of course, when the search page is actioned via those links, article results show up, that were also visited by the bots.
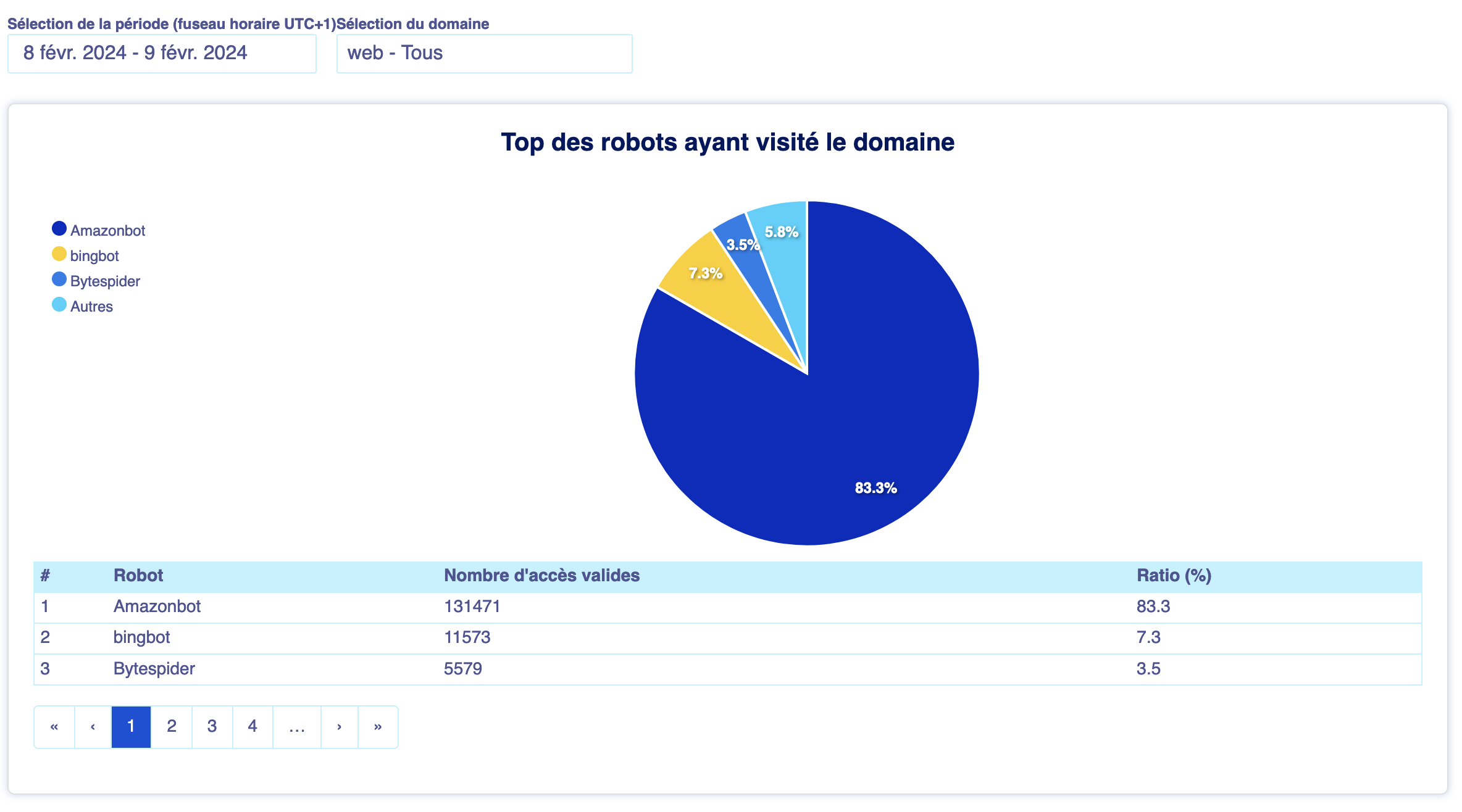
We can see that AmazonBot specifically got lost in this search page, with over 230.000 display attempts in a single day. So that explains a part of the high load, but why did the website issue outbound requests in response to that ?

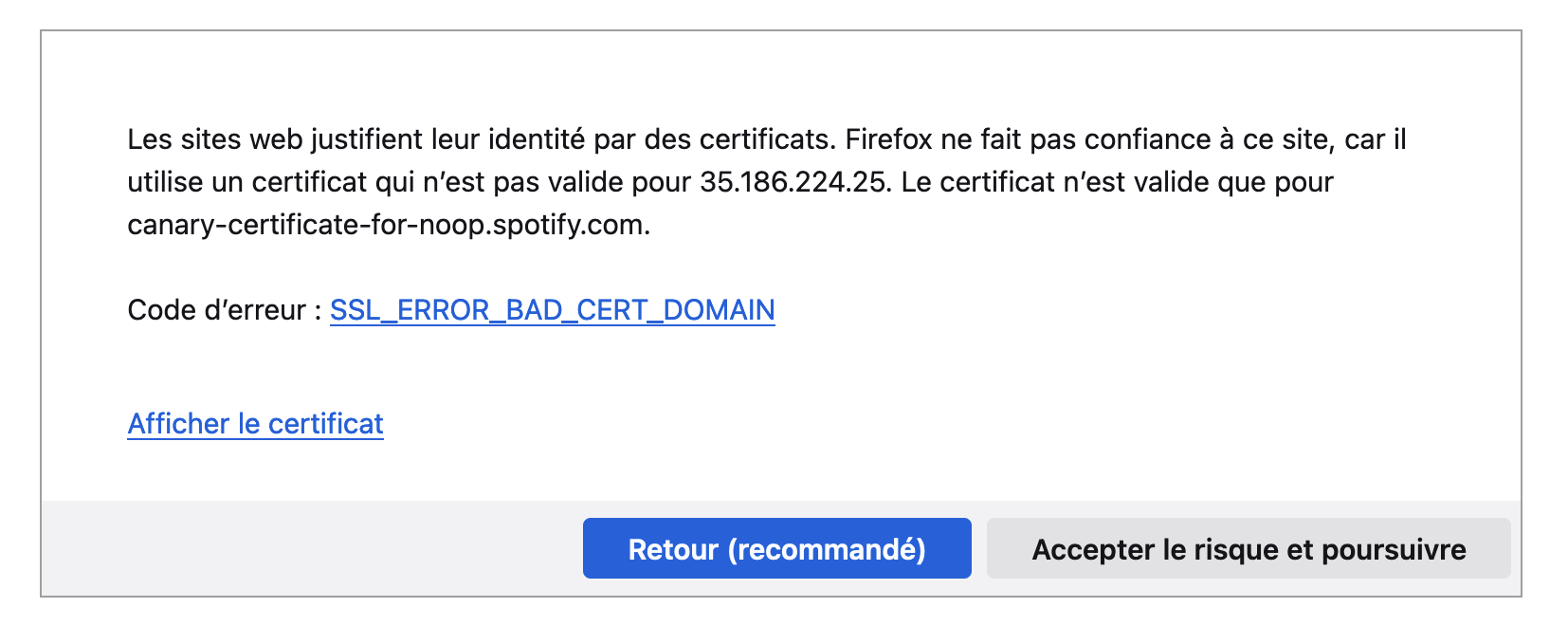
Going through the outbound requests logs, I see hundreds of thousands of connections to three different IPs. I took the first one and thought I’d just visit it before doing a reverse DNS lookup :

I landed on a firefox HTTPS warning, telling me that the certificate wasn’t valid for the IP, but only for a spotify-owned subdomain. The other two IPs belonged to Bandcamp and Youtube.
The website uses player embeds for a few streaming providers, among which are YouTube, Spotify and Bandcamp. I googled a bit to learn about the engine’s oEmbed implementation. Basically, if you have an URL that is known to point to a provider capable and allow-listed to provide an iFrame snippet for some content, the CMS will fetch an URL at that provider to fetch the iFrame snippet. The goal is allowing the user to use a canonical URL for the content, while the streaming provider can sometimes update its integration code without the user changing it. Also, it is “easier” for an user to copy and paste an URL rather than an iFrame integration snippet. So, you paste in an https://open.spotify.com/<track or album ID> URL, and the website’s engine pings the given provider.
That explains the three outbound destinations. But surely, a CMS used by a community that large would cache those requests, wouldn’t it ?

Indeed, it does. I skimmed the source of the oEmbed implementation to be sure of that, and oEmbed integration results are indeed cached. So, why would the website issue requests for each page view, since that’s the only coherent hypothesis linking high bot traffic and high outbound request count ?
Well, posts are not written using the vanilla editor provided by the CMS, but with an alternative editing method, very popular in this CMS’s community, offering “custom fields” in an advanced way, to allow a website administrator to create structured content types. Looking a bit into those structured fields structure, I saw that indeed, oEmbed field types were used, but only for Spotify, YouTube and Bandcamp while the other providers used a regular text field that was converted to the right iFrame integration code by the website author.
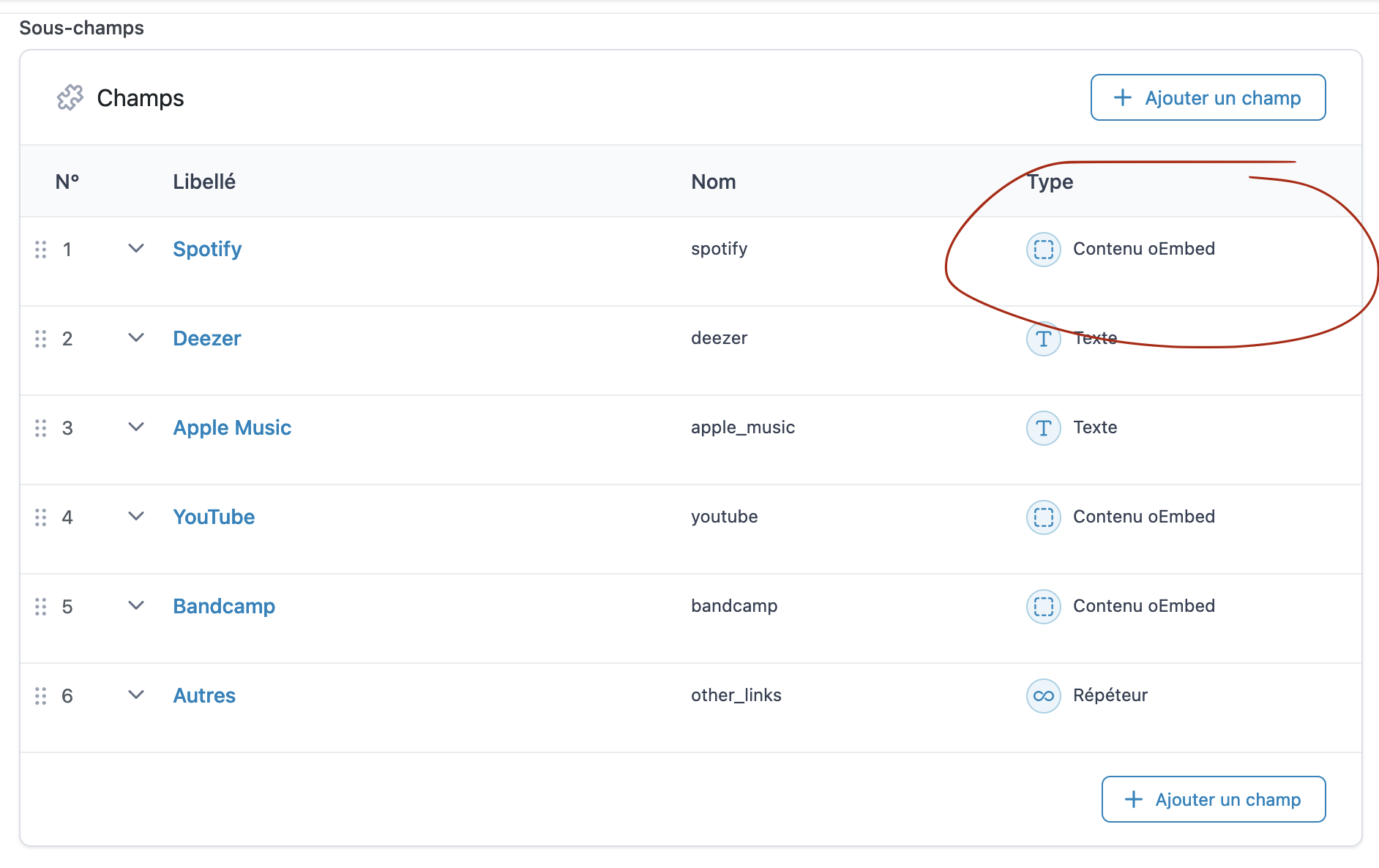
I started to have a very strong suspicion that the “structured fields” plug-in did not use the correct oEmbed implementation provided by the CMS engine, but an alternative one that skipped caching. That would be a very dangerous default behavior, but who would be surprised of that in this ecosystem ?
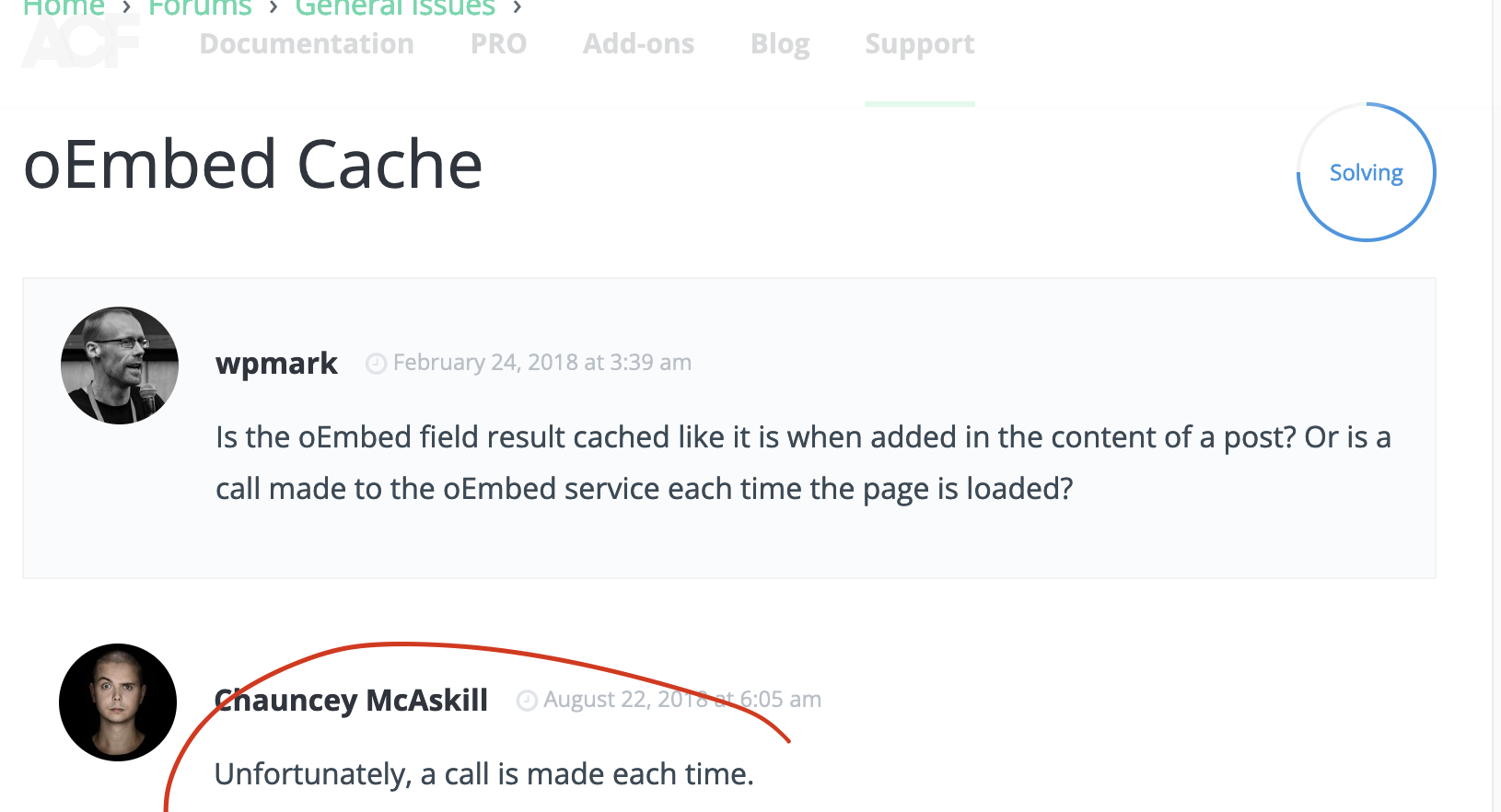
A bit of googling landed me on this plug-in’s support forum, where someone asked this very question in February 2018.
Q : Is the Embed field result cached like it is when added in the content of a post? Or is a call made to the Embed service each time the page is loaded? A : Unfortunately, a call is made each time.
Fortunately, there exists a way to bypass this behavior upon display. The AmazonBot continued getting lost for a while, but the outbound requests dropped to zero, and the website came back up and not overloaded at the exact time I stopped (well, added caching of those embed results) this behavior.
That leaves a few open questions though :
- Why didn’t the oEmbed providers block this high traffic requester ?
My guess is that 18k requests per minute is only 300rps and that’s nothing unusual for those providers. - Why didn’t the hosting provider alert that the website had very suspicious behavior for a simple content website on shared hosting ?
Well, they did alert of something, mainly that the website was using too much CPU and that it could be wise to get a higher hosting plan. They were right in a way, but in retrospect I would have been happy to be transferred a “your website looks like it’s DOSing those IPs” e-mail. - How can that kind of default behavior exist on a so widely used plug-in on a crushingly widely used platform ?
This one, I don’t have educated guesses. Maybe people are used to this kind of website being slow and buggy because that’s just the way it often is ? Maybe this oEmbed thing isn’t very widely used in combination to high bot traffic ?
This kind of debug is quite hard to reason about, because it’s about discovering the source of unwanted behaviors that aren’t visible in user code. The average Elixir application I work on, even if it interacts with a lot of third-parties, does not spontaneously do things that it isn’t supposed to do. This leads to successive discoveries that are hard to believe, because why would a website do that ? The original author did not write code, nor intend, to DOS Spotify. This isn’t written anywhere.
It was fun to explore though and I’m suspecting a transition to an almost fully static website will help let go of these behaviors.