2D SVG shapes to lead-type 3D models ? A failing attempt.
A notebook about trying to find a silver bullet to automate a tedious manual process.
After a bit of manual work, I decided to automate this process.
It turns out that this process was absolutely non-trivial, and that I’d better develop a strict framework and guidelines around doing it manually.
Note : I’m in the process of migrating this article to this new blog.
Live samples and syntax highlighting weren’t brought back to life yet.
A first manual attempt
How does a lead character look ?
A bit of context is needed on what I'm trying to attain. I'd like to be able to be self-sufficient on the production of lead-like movable characters and shapes.

In Toulouse, the place I live in southwestern France, some workshops offer their CNC machining services and are able to produce aluminum plates at the correct height for a typographic press. But I'd like a typographic press to become an experimentable tool, rather than a final process, marked by the need to be absolutely certain of a layout before sending it to be engraved.
A distinct, but crucial feature of engraved aluminum plates or lead type was that the shape to be printed wasn't just extruded out of its substrate. The shape emerges of a pillar similar to an offset of its outline. On the figure below, you can see this slight offset. Extruding a shape is obviously simple, but this gives strength to the character.

How can we reproduce this slope manually ?
Even more crucially, if I'm headed towards lost PLA aluminum casting with 3D printed counterforms, meaning another bee's nest, I'll start by using plastic characters to print. After some failed attempts years ago, they failed under pressure if the shape of the letter wasn't strengthened by this light slope.
This slope is quite tedious to generate manually : I start from path data from Inkscape or Illustrator, import it into Blender, extrude it, offset it with Offset Scale (Alt + S), intersect it with a regular cube to suppress distorsion from Offset Scale, export it to a STL file, clean it in Netfabb, and then slice it in Cura.

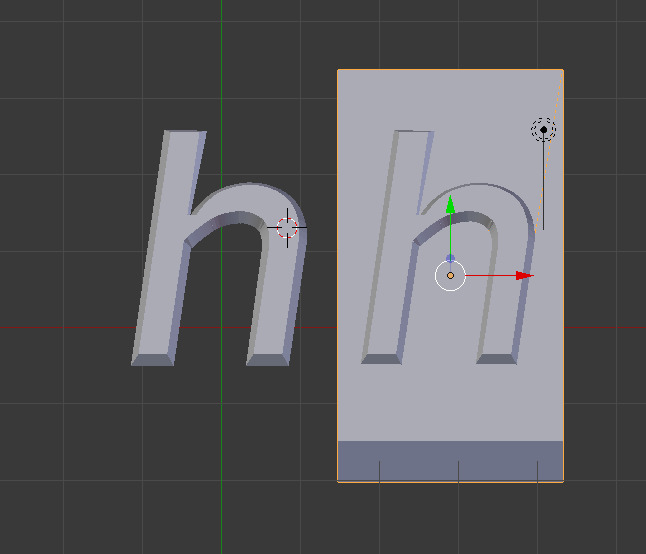


This process is tedious. I thought I could automate it, starting from SVG path data. The rest of this page shows how this was way more complex than I thought, and, after a week of exploration, it's obvious I should have thought of intersecting paths, paths with holes, concave shapes, and a lot more traps.


Creating a lead type 3D model with its slope, from raw SVG path data.
SVG path data structure
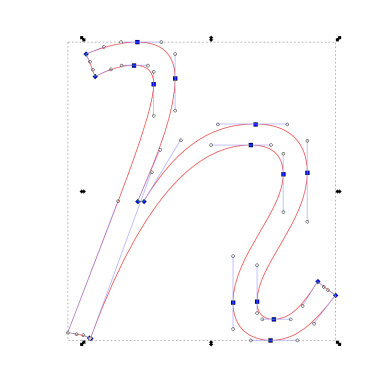
Here's a box containing an outlined "h" in Vulf Mono Light Italic, a typeface by Oh No type company. We'll try to understand how this list of instructions work.
<path style="stroke:#130000;stroke-opacity:1;stroke-width:4.42498882;stroke-miterlimit:4;stroke-dasharray:none;paint-order:markers stroke fill;fill:#ff0000;fill-opacity:1" d="m 205.47289,169.14572 c -1.08,0 -1.56,-0.6 -1.56,-1.64 0,-3.4 4.68,-7.48 4.68,-12.04 0,-3 -1.88,-4.52 -4.84,-4.52 -3.52,0 -6.96,1.48 -10.4,7.2 h -0.56 c 2.08,-4.8 3.48,-8.48 3.48,-11.48 0,-2.24 -1.28,-3.36 -3.52,-3.36 -1.52,0 -3.12,0.44 -4.8,1.12 0.36,0.68 0.64,1.44 0.84,2.08 1.48,-0.68 2.48,-1.04 3.64,-1.04 1.28,0 1.84,0.6 1.84,1.76 0,2.92 -3.32,10.88 -8,23.16 0.8,0.12 1.44,0.24 2,0.48 l 0.12,0.04 c 5.68,-15.48 11.24,-18 14.92,-18 1.88,0 3.04,0.8 3.04,2.72 0,3.52 -4.68,7.64 -4.68,11.96 0,2.44 1.64,3.52 3.48,3.52 2.48,0 4.04,-1.56 6.08,-4.2 -0.72,-0.48 -1.12,-0.8 -1.68,-1.28 -1.4,2.28 -2.52,3.52 -4.08,3.52 z" id="path1702" />
According to the SVG Pocket Guide, the "d" attribute contains instructions with mnemonics and values. We'll also keep the SVG Stroke spec in a tab, because an implementation of a stroke algorithm is outlined. W3 SVG spec
| mnemonic | meaning | observations |
|---|---|---|
| m or M | move to | akin to a pen lift. a path must start with a M command. |
| z or Z | close path | closes the current subpath. draws a straight line between that point and the initial point of the subpath. If a M instruction follows, the next subpath starts at the newly-defined coordinate. Else, the next subpath starts at the same point. |
| L or l | draw | draws a line from the current point to the next point. The new point becomes the current point. L means that following positions are absolute, l means relative. |
| H or h | draw an horizontal line | Akin to L,l H and h denote absolute and relative positioning. |
| V or v | draw a vertical line | Akin to L,l and H,h, V and v denote absolute and relative positioning. |
| C or c | Draw a cubic Bézier curve | Draw a curve from the current point, using (x1,y1) as the first control point, and (x2, y2) as the second control point. The same uppercase/lowercase to absolute/relative mapping is effective. |
| S or s | Draw a cubic Bézier curve, with reflection | Draw a curve following a C statement, with tensor points mirrored. |
| Q or q | Draw a quadratic Bézier curve | Quadratic Bézier curves have a single (x1, y1) tensor. |
| T and t | Draw a quadratic Bézier curve | Akin to S and s following a cubic Bézier curve, T and t are mirroring statements for a quadratic Bézier curve. |
| A and a | Draw a segment of an ellipse. | A statements draw a segment of an ellipse, given a start point, end point, x radius, y radius, rotation of the ellipse, and direction. Two additional parameters, large-arc and sweep, are flags giving directions on which part of the ellipse should be drawn. |

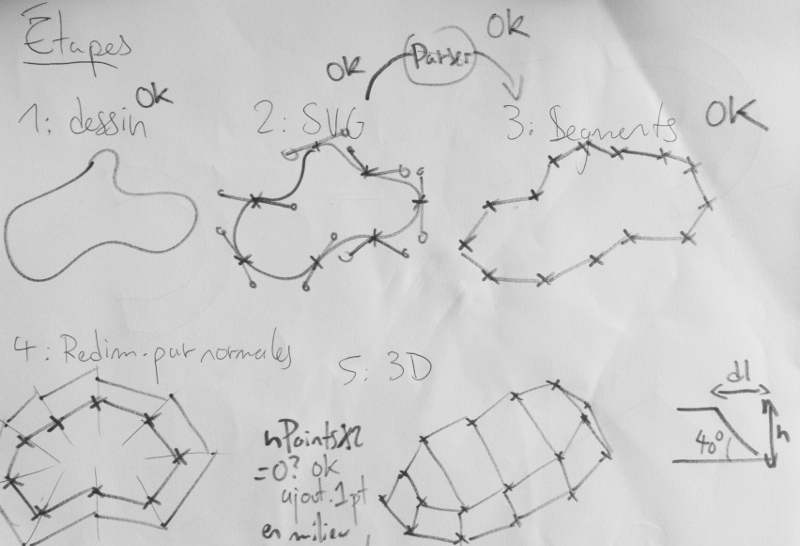
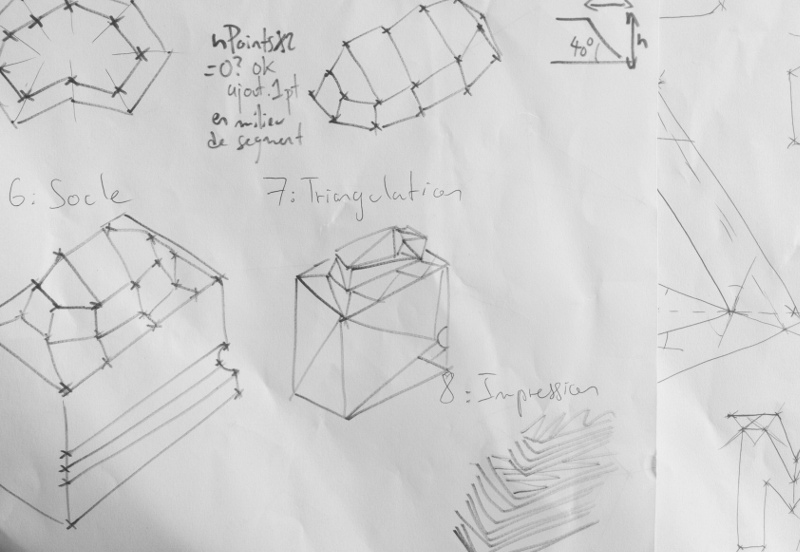
With those elements in mind, we can decipher the above svg path, and annotate it :
m 205.47289,169.14572 // Move to (205.47289, 169.14572) c -1.08,0 -1.56,-0.6 -1.56,-1.64 // Cubic Bézier (relative, from last point, first tensor at (-1.08, 0), second tensor at (-1.56, -0.9), end point at (-1.56, -1.64))
Introducing a clearer notation for our research
This notation is a bit hard to read, so we'll introduce "functions", that return the current point. Points will be a kind of tuples (x, y).
m 205.47289,169.14572 // move((205.47289, 169.14572)) c -1.08,0 -1.56,-0.6 -1.56,-1.64 // cubicRel(lp, (-1.08,0), (-1.56,-0.6), (-1.56,-1.64))
We can see a pattern emerging : a dependency on a global "current point" state. To write a parser/an interpreter, this isn't too uncommon. We could also think of this in a functional way, and use referential transparency at our advantage :
m 205.47289,169.14572 // move((205.47289, 169.14572)) -> returns ((205.47289, 169.14572))
The last sample with two instructions becomes :
cubicRel((-1.08,0), (-1.56,-0.6), (-1.56,-1.64))
If we introduce the following instruction in the original path, another cubic Bézier curve, our path now looks like :
cubicRel(
cubicRel(
move((205.47289, 169.14572)),
(-1.08,0), (-1.56,-0.6), (-1.56,-1.64))
, (0,-3.4), (4.68,-7.48), (4.68,-12.04))Well. As much as I like lisps, maybe a parser with a global state will be enough. I only aim to parse svg paths, so the table defined earlier on will be enough to guide us. Maybe, even, we could just avoid a global state and produce a list of instructions taking the last point as an argument, and reevaluating everything to absolute coordinates.
move((205.47289, 169.14572)) // -> (205.47289, 169.14572) cubicRel((205.47289, 169.14572), (204,39289, 169.14572), (203,91289, 168,54572), (203,91289, 167,50572)) // -> (203,91289, 167,50572)
This seems quite easy to generate ! Let's write the minimal amount of code to parse those two declarations to an AST, and produce this kind of pseudo-instruction list. I'm writing all of this in a html document, so I'll write in JS to get live examples quick and running.
Parsing SVG path data to an AST with a reduced grammar
Let's start by drafting a grammar allowing those two instructions to exist. This syntax and prose is vague compared to a real grammar description language, and the SVG spec contains a backus-naur form of the SVG grammar.
But it should read :
- a path is made of instructions.
- instructions can be move or cubic.
- instructions take a various number of points.
- a point is made of two numbers separated by a comma, between parentheses.
- a number is an optional hyphen, followed by multiple digits, an optional dot, and maybe multiple digits again
- finally, a digit is any character in [0 1 2 3 4 5 6 7 8 9]
path = instructions*
instruction = move point | cubic point point point point
point = '('number','number')'
number = '-'?digit+'.'?digit+
digit = [0-9]This is enough to write a basic parser that understands standalone move and cubic instructions.
This example uses the following JS implementation : we have a regex to identify points, and define regexes for move and cubic instructions. We only tokenize the input by splitting at newlines, trimming the resulting lines, and filtering empty ones.
const Point = function(x, y) { this.x = x; this.y = y; };
const pointR = '(?:([-]*\\d+\\.?(?:\\d+)?),([-]*\\d+\\.?(?:\\d+)?))';
const moveRegex = new RegExp(`m\\s*${pointR}`, 'i');
const cubicRegex = new RegExp(`c\\s*${pointR}\\s${pointR}\\s${pointR}`, 'i');
const matchesToPoints = (token, matches) => {
if (!matches) throw new Error(`Couldn't parse token ${token}`);
const points = matches.slice(1);
if (points.length % 2 !== 0) throw new Error(`Instruction contains an uneven number of coordinates.`);
const out = [];
for (let i = 0; i < points.length; i += 2) {
out.push(new Point(points[i], points[i + 1]));
}
return out;
};
const move = token => matchesToPoints(token, token.match(moveRegex));
const cubic = token => matchesToPoints(token, token.match(cubicRegex));
const lex = (tokens) => {
return tokens.map(t => {
switch (t.charAt(0).toLowerCase()) {
case "m":
return {type: 'Move', params: move(t) };
break;
case "c":
return {type: 'Cubic', params: cubic(t) };
break;
default:
return;
break;
}
});
};
const tokenize = text => text.split('\n').map(a => a.trim()).filter(a => a);
export const parse = text => lex(tokenize(text));Parsing realistic input
Still, we're assuming many things here. We need a list of newline-separated instructions, starting with their mnemonic.The input format is a list of instructions, without newlines, and mnemonics are only present at an instruction change. That means m point \n c point point point \n c point point point won't ever be present. We need a way to keep track of the current type of instruction, and take points accordingly.
Let's do this !
We need to have a kind of state-machine, starting at an undetermined state, and chewing through text obeying rules for the current state, and a list of transitions between states. Here's some pseudo-code defining those principles. We'll write a basic parser that aims to keep track of the current point and generate a list of independent instructions.
We'll also translate all coordinates to absolute by adding the current point's absolute coordinates to every point present in a relative version of an instruction.
States : {"Undefined":0,"Move":1,"Cubic":2,"End":3}
Tokenizing : trim, then split at spaces.
[]
Lexing : transform this into a list of instructions.
[]
The JS code present in this sample, annotated :
// "Enums" for positions and parser state
export const STATES = fakeEnum('Undefined', 'Move', 'Cubic', 'End');
const POSITIONS = fakeEnum('Absolute', 'Relative');
// Point string to absolute point, depending on
// the carried current point and positioning mode
const strToPt = (str, curr, pos) => {
const c = curr ? curr : { x:0, y:0 };
if (!pointReg.test(str)) throw new Error();
let [expr, x, y] = str.match(pointReg);
if (pos === POSITIONS.Relative) { x = Number(x) + c.x; y = Number(y) + c.y; };
return new Point(Number(x), Number(y));
}
// Move and Cubic AST node generators
const move = (tokens, index, currentPoint, pos) => {
const [p1] = [tokens[index]]
.map(t => strToPt(t, null, pos));
const instr = { type: 'Move', points: [p1] };
return { instr, current: instr.points[0] };
};
const cubic = (tokens, index, currentPoint, pos) => {
const [p1, p2, p3] = tokens.slice(index, index + 3)
.map(t => strToPt(t, currentPoint, pos));
const instr = { type: 'Cubic', points: [currentPoint, p1, p2, p3] };
return { instr, current: instr.points[3] };
};
The lexing function, carrying state and switches, acts as a transition table :
// For each token, depending on the state we're in, we'll try to parse a point or change state.
// This is naïve, and will break on invalid input.
const lex = function(tokens) {
let state = STATES.Undefined;
let pos = POSITIONS.Absolute;
let currentPoint = null;
let instrs = [];
let i = 0;
const setPos = (token) => { pos = isUpperCase(token) ? POSITIONS.Absolute : POSITIONS.Relative; };
while (state !== STATES.End) {
const token = tokens[i];
if (state === STATES.Undefined) {
switch(token.toLowerCase()) {
case "m":
state = STATES.Move;
i += 1;
break;
case "c":
state = STATES.Cubic;
i += 1;
break;
}
setPos(token);
} else if (state === STATES.Move) {
switch(token.toLowerCase()) {
case "c":
setPos(token);
state = STATES.Cubic;
i += 1;
break;
default:
try {
let { instr, current } = move(tokens, i, currentPoint, pos);
instrs.push(instr);
currentPoint = current;
} catch(e) {}
i += 1;
break;
}
} else if (state === STATES.Cubic) {
switch(token.toLowerCase()) {
case "m":
setPos(token);
state = STATES.Move;
i += 1;
break;
default:
try {
let { instr, current } = cubic(tokens, i, currentPoint, pos);
instrs.push(instr);
currentPoint = current;
} catch(e) {}
i += 3;
break;
}
}
if (i >= tokens.length -1) state = STATES.End;
}
return instrs;
};
Rendering to a list of expressions & a canvas
Well, it seems to work for those two instructions ! The current point is carried on, and we have independent instructions that are sufficient to render something.
We can try to render it to a list of expressions, akin to an example shown higher, then to a canvas.
Rendering to text is just a matter of pretty-printing AST nodes, while rendering to a canvas is conveniently a 1-to-1 mapping of our instructions to CanvasRenderingContext2D methods.
- move(point) -> c2d.moveTo(x, y)
- cubic(point, point, point, point) -> c2d.moveTo(...points[1]), c2d.bezierCurveTo(...points[1-3])
Adding H,h, L,l, and V,v instructions
Nice ! We're now able to transform raw SVG path data to an abstract syntax tree, and transform it back to a list of absolute-positioned subpaths, or draw it to a canvas. But many instructions are missing, and the examples to this point just silence errors.
Let's implement h, l, and v instructions. H and V are just special cases of L where the current point Y or X coordinate is carried on.
Converting curves to segments
Our next step is a conversion from curves to only-segments path data.
This will be quite a stretch, since my math has really faded since school. Of course, someone has already solved this before, and an article on Adaptive Subdivision of Bezier curves written by Maxim Shemanarev gives us a reference implementation in C++. That will be easy to convert. I'll take the most naïve one, given at the start of the article, and, no matter the curve, will generate 10 lines out of it.
We can see the result is still quite pleasant.
Transforming our original path to an offset reflection
I'm not sure how to proceed for this one, but : for three points (or vector) a, b, and c, the point b' will be equal to the vector b added to the vector going from the middle of the segment ac to b.
Let's draw points instead of lines now, by writing a converter from instructions to points. A brute version would be to reduce instruction points to a list, then deduplicate adjacent items.
Meaning : move([1,0]), line([1,0] [5,0]), line([5, 0] [7,2]) becomes [1,0],[1,0],[5,0],[5,0],[7,2] then [1,0],[5,0],[7,2].


We now have points instead of curves, and a method, we'll proceed to do this scale-up algorithm. Or will we ?
Point fog rendering, and a test of an intuition about path segment normals.
It happens that the problem I'm trying to solve is really non-trivial. With a bit more research (and stumbling on the right terms), what I'm trying to solve is called "outward polygon offsetting". A stackoverflow answer gave me some direction. This survey gave a nice answer too. What if a simpler strategy could work ? I could reimplement a C++/C#/Delphi library called Clipper, or find a "nice enough" heuristic. I could copy-paste a stroke algorithm and take its output before rendering. Let's dive into Inkscape sources. Or into Clipper, and extract the subroutine and its dependencies.
For now, let's test with a library found on npm, polygon-offset. It seems nice enough to be free of assumptions about how you describe a polygon, and is satisfied with an array of points.
We have an offset outline, and implementing this by hand would have been a nightmare. Can we make this 3d ? I'll take This example from three.js as a starting point. What was meant to be an "implement everything" exercise turns more and more to a "cobble stuff together" exercise. But I now have a nice stack of papers to read. Clicking "download" on three.js homepage yields a 250MB zip file, I should have known what territory I was stepping into.
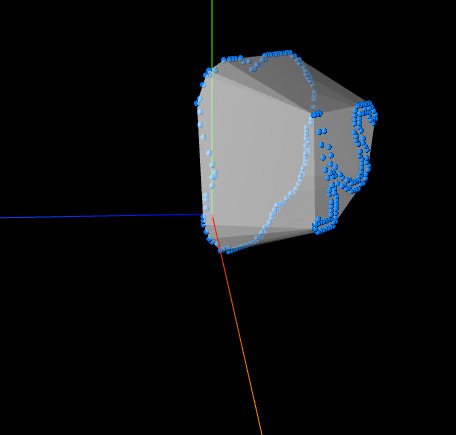
This test, an adaptation of THREE.js's example "ConvexGeometry", reveals that a naïve culling approach won't be enough: our polygons are concave.
Let's dive into polygon triangulation, I guess ? There are naïve algorithms available, and I'll then proceed to implement stitching between the original and offset shape.